词法分析
作用
读入源程序的输入字符,将它们组成词素,生成并输出一个词法单元序列,交给语法分析器
过滤掉注释和空白
将编译器生成的错误信息与源程序的位置联系起来
正则表达式
正则表达式是一种用来描述词素模式的重要表示方法
每个正则表达式表达一个语言$L(r)$
正则定义

正则表达式的扩展
除了并、连接、Kleene闭包
+表示一个或多个实例
?表示零个或一个实例
$a_1 | a_2 | \cdots | a_n$可缩写为$[a_1a_2\cdots a_n]$
另外Lex还有扩展的表示方法
词法单元的识别
知道了如何用正则表达式表示模式,还需要知道如何写出一段代码,代码能够检查输入字符串,并在输入的前缀中找出一个能和某个模式匹配的词素
状态转换图
模式可被转换成具有特定风格的流图,称为“状态转换图”
三个有关状态转换图的重要约定:
- 某些状态为接收状态,表明已经找到了一个词素
- 如果相应的词素其实并不包含最后几步使达到接收状态的符号,在这个状态加上几个*,表示其实要回退几步
- 有一个状态是初始状态
有穷自动机
有穷自动机是识别器,只能对每个可能的输入串简单地回答“是”或“否”
分为两类,NFA和DFA
NFA(不确定的有穷自动机)对其边上的标号没有任何限制
DFA(确定的有穷自动机)对于每个状态和自动机输入字母表中的每个符号,有且只有一条离开该状态、以该符号为标号的边
NFA和DFA都可以被表示为图的形式,与状态转换图相似但不完全相同
NFA
由以下的部分组成:
- 有限状态集合S
- 输入符号集合$\sum$
- 转换函数,为每个状态和输入符号给出后继状态集合
- 一个开始状态s
- 一个子集F被指定为接收状态集合
DFA
是NFA的特殊形式
- 没有对于$\in$的转换动作
- 对于每个状态s和每个输入符号a,有且只有一条标号为a的边离开
算法
NFA转成DFA
思想是用子集构造法让DFA的每个状态对应NFA的一个状态集合
最坏情况下DFA的状态数是NFA状态数的指数级,但算法基于事实:对于真实语言,NFA和DFA状态数大概相同
输入:NFA N
输出:DFA D
定义一些函数,s表示N的单个状态,T代表N的一个状态集
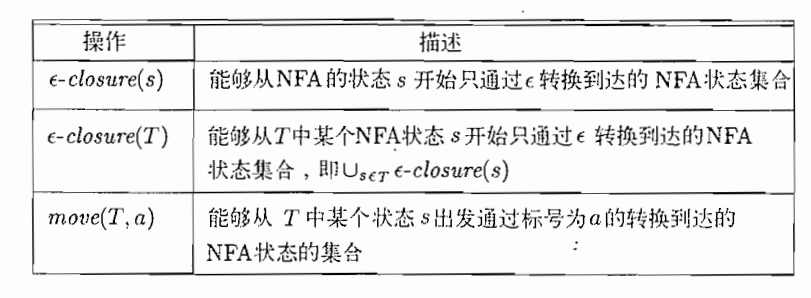

D的开始状态是$\in-closure(s_0)$,接收状态是所有至少包含了N的一个接受状态的状态集合
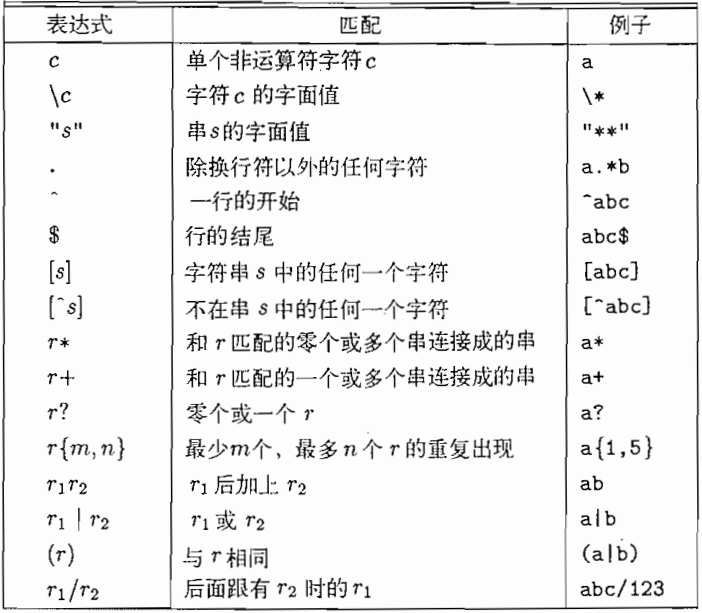
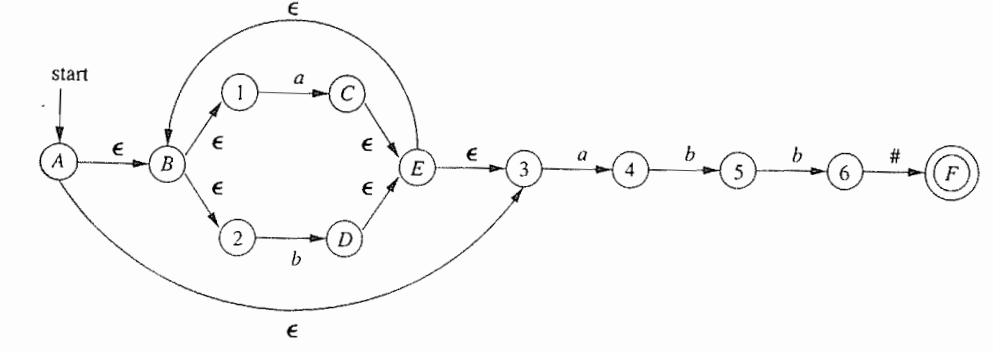
从正则表达式构造NFA
思想:沿着正则表达式的语法分析树自底向上递归处理
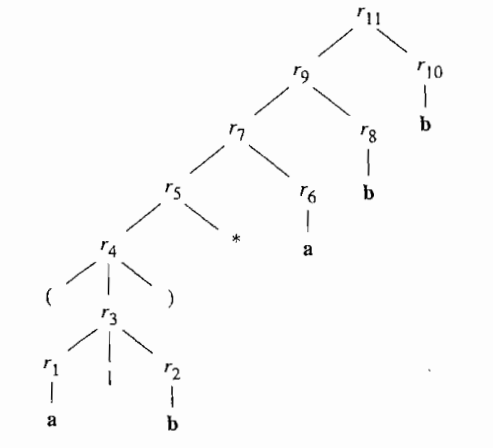
输入:字母表$\sum$上的一个正则表达式r
输出:一个接受$L(r)$的NFA N
按如下规则从下都上拼起来
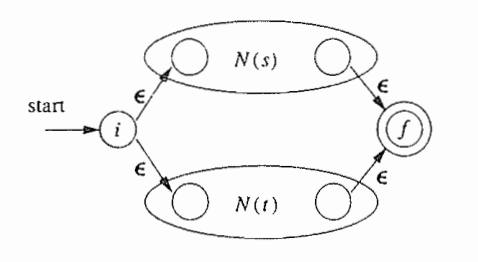
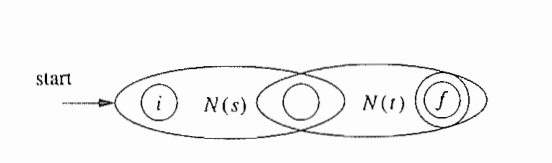
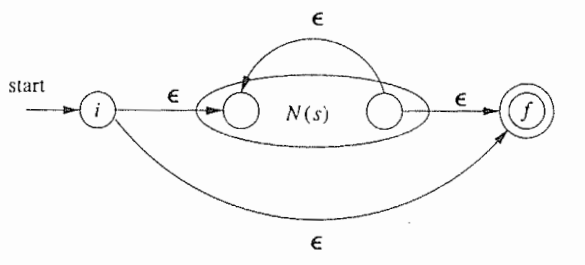
从正则表达式构造DFA
如果一个NFA状态有一个标号为非$\in$的离开转换,称这个状态是重要状态
子集构造法算$\in-closure(move(T, a))$的时候实际上只用了T里的重要状态
所以应用子集构造法时,两个NFA可以被认为是一致的当:
- 它们有相同的重要状态
- 要么都包含接受状态,要么都不包含
如果该NFA是通过正则表达式生成的,那么还有性质每个重要状态对应于正则表达式中的某个运算分量
而且正则表达式构造出的NFA只有一个接受状态,该接受状态因为没有离开转换而不是重要状态
因此可以用扩展的正则表达式r(#),构造过程结束后,有#的离开转换的状态都是接受状态
NFA的编号状态和抽象语法树的位置是对应的
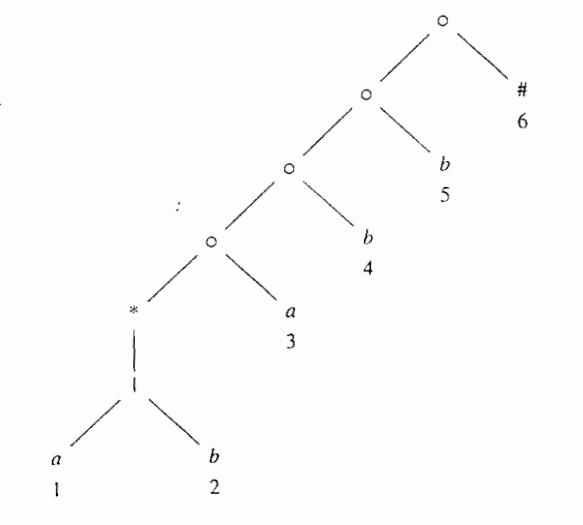
要由正则表达式直接构造DFA,先要构造出抽象语法树
然后计算四个函数

nullable,firstpos,lastpos很好算
followpos的计算规则为:
- 如果$n$是一个cat结点,且其左右子节点分别为$c_1,c_2$,那么对于$lastpos(c_1)$中的每个位置i,$firstpos(c_2)$中的所有位置都在$followpos(i)$中
- 如果$n$是star结点,并且i是$lastpos(n)$,那么$firstpos(n)$中的所有位置都在$followpos(i)$中
输入:一个正则表达式r
输出:一个识别$L(r)$的DFA D
方法:
- 画出抽象语法树T
- 计算出四个函数
- 使用如图算法

最小化DFA状态数
对于同一个语言,存在多个识别此语言的DFA
