MapReduce
Introduction
MapReduce旨在提供抽象,让没有并行编程基础的人也能利用分布式系统的资源
Programming Model
map (k1, v1) -> list(k2, v2)
reduce (k2, list(v2)) -> list(v2)
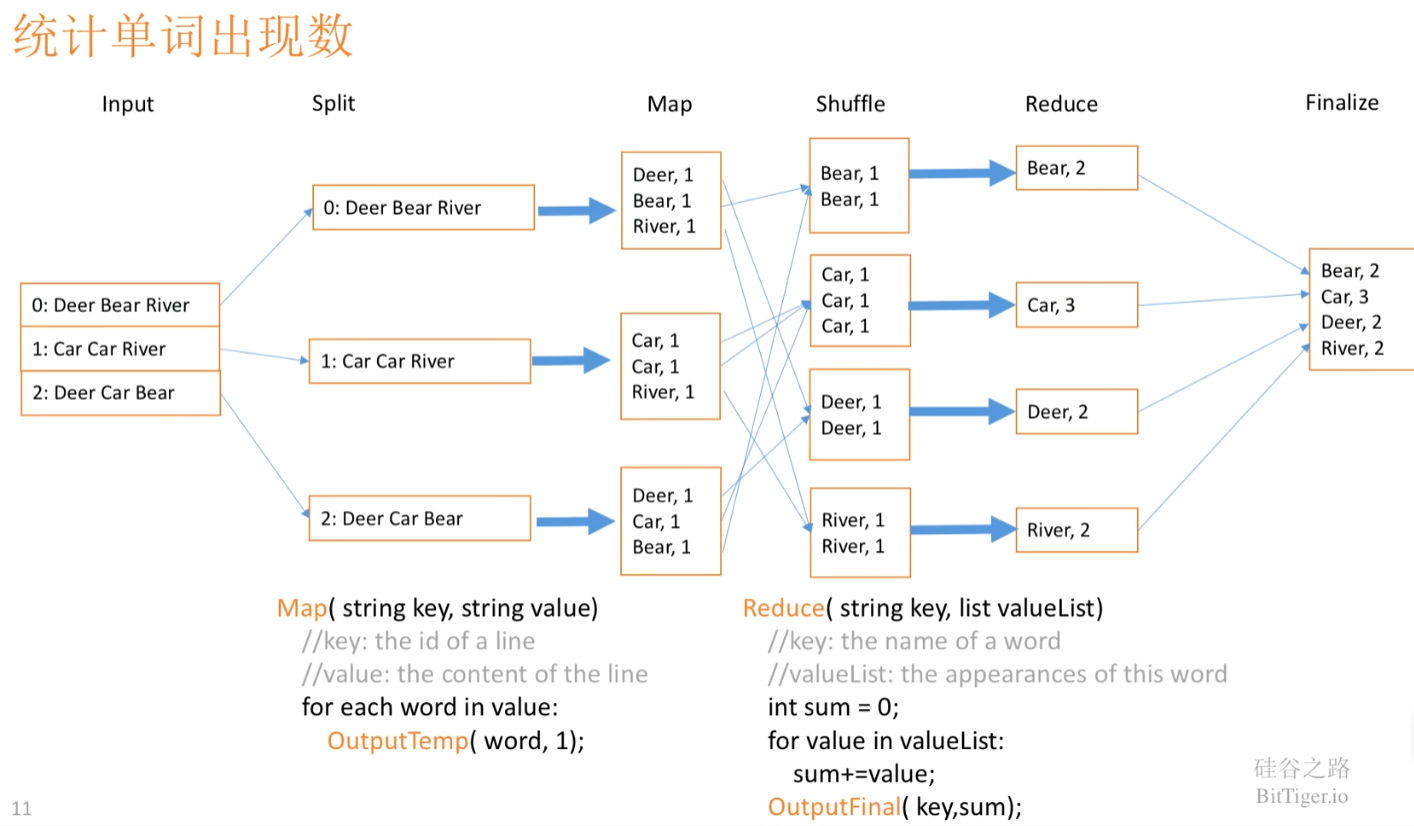
e.g. 单词记数
map (文档名,文档内容) -> list(单词, 出现次数)
reduce (单词, list(出现次数)) -> list(出现次数)
思想核心是经过谷歌大量重复的编写数据处理类的程序,发现所有数据处理的程序都有类似的过程:
将一组输入的数据应用map函数返回一个k/v对的结构作为中间数据集,并将具有相同key的数据输入到一个reduce函数中执行,最终返回处理后的结果
这个计算模型抽象出来就是MapReduce,而且由于map的过程可在多台机器上互无依赖地并行执行,有利于并行化,reduce过程同理
reduce过程要在map过程全部结束后开始执行
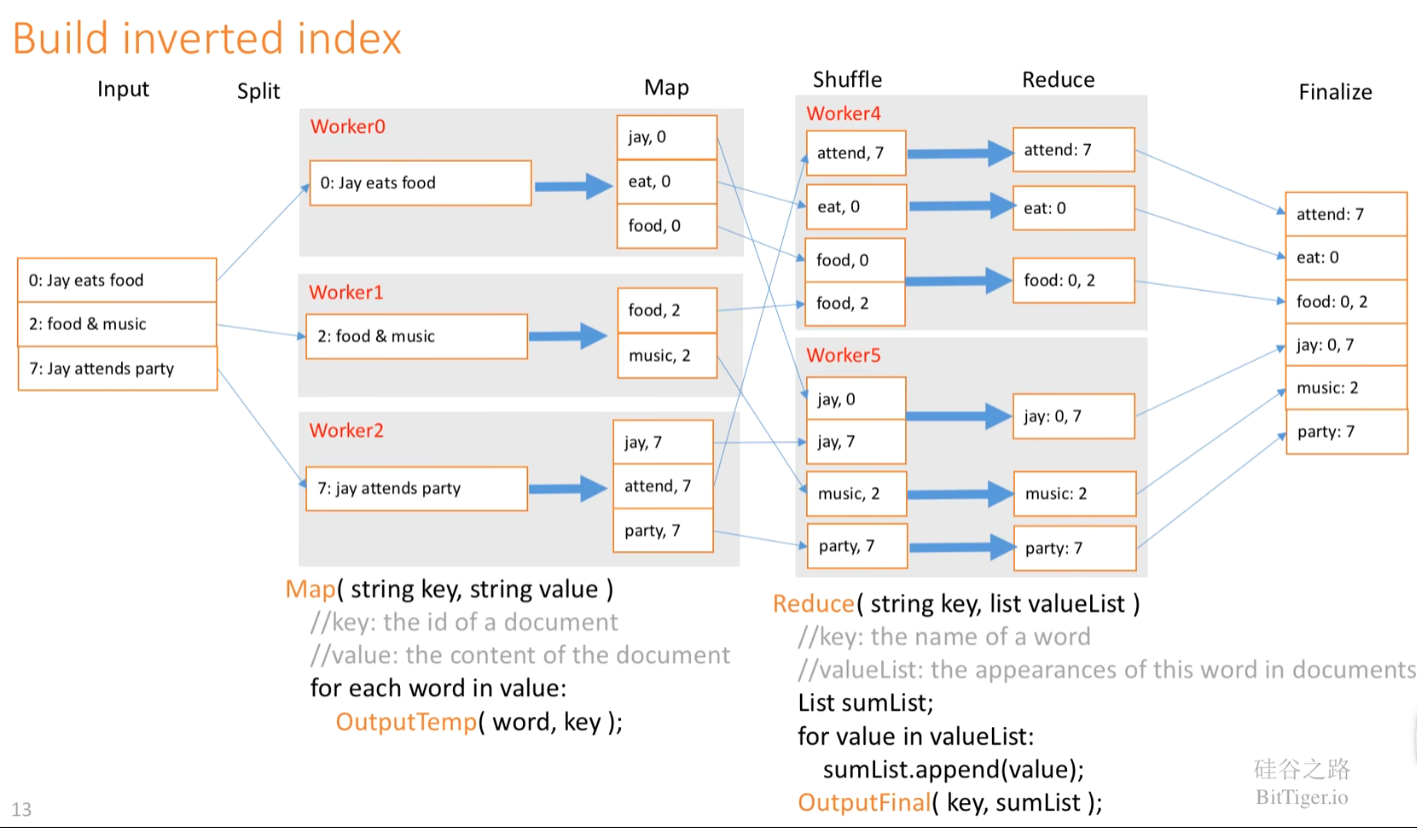
Implementation
OverView
输入文件会被分成M份,每份大小可由user调参
是主从式并行,主节点给工作节点分配任务,有M个map任务和R个reduce任务
分配到map任务的工作节点会把输入数据里的KV对解析出来,传入Map函数,得到的中间数据集在内存中缓存
周期性地,缓存中的KV对会被写入本地磁盘,在磁盘上被分成R块(根据partition函数,每个map工作节点都输出R个文件,每个对应一个reduce任务),这些KV对的地址会被传回给主节点
当一个reduce工作节点被主节点告知了KV对的地址,会通过RPC去读这些数据,然后读完以后,按key给这些KV排序,这样相同key的数据就挨着了;如果中间数据集量太大,不能全部放入内存,会用外部排序
reduce工作节点遍历排序好的数据,每遇到一个key就将这组传给Reduce函数,输出会写到该reduce分区最终文件末尾(最后会有R个输出文件)
所有工作节点结束工作以后,主节点唤醒用户程序,MapReduce调用返回值给用户程序
关于5中要用RPC来读数据的原因(from gpt 4.0):Map阶段处理的数据被存储在map工作节点的本地磁盘上。当Reduce阶段开始时,reduce工作节点需要从多个map工作节点读取这些数据以进行进一步处理。这里涉及的是跨网络的数据访问,即reduce工作节点需要远程访问map工作节点的数据。RPC在这个场景中被用作一种高效(抽象了底部细节)、可靠(RPC有自动重试机制等)的远程数据访问机制
Master Data Structures
主节点要维护每个map和reduce任务的状态(空闲,进行中,完成),正在工作的机器的ID,map任务完成产生的R个中间文件的位置和大小
Fault Tolerance
Worker Failure
主节点会周期性地ping工作节点,如果其没有及时应答就视作失效
然后以下任务会重新执行:这个坏掉的工作的节点正在进行的map/reduce任务,已经完成的map任务
需要重做已完成的map任务是因为map任务的输出在该工作节点的本地磁盘上,现在这个节点坏了,之前的输出也拿不到了,而已完成的reduce任务不用重新做因为输出文件在全局文件系统里
Master Failure
直接结束MapReduce,让客户端决定要不要重试
Semantics in the Presence of Failures
MapReduce对确定性操作提供强语义保证
Locality
网络带宽很珍贵,所以一些局部性措施会用来减少网络带宽的使用
如主节点会尽量把map任务分配给本来就有一份输入文件的节点上
一个map任务结束通知主节点后,主节点可以立即通知一个reduce任务拉取文件,不必等所有map任务结束
Task Granularity
M和R应远大于工作节点数
Backup Tasks
为了避免某些工作节点拉跨,在所有任务快结束时,会为还在进行中的任务启动备份任务,两者中谁先完成都算该任务完成
Refinement
Partitioning Function
默认划分函数为 hash(key) mod R
如果中间数据集的key是URLs,用hash(Hostname(urlkey)) mod R
Ordering Guarantees
为了减少reduce任务的负担,输出的每个map任务的中间文件都是保证按key递增有序的
Combiner Function
Combiner函数是运行在map节点上的,功能和Reduce函数一样
是为了防止出现如单词记数中the这个单词过多导致(the, 1)过多,很占网络带宽
所以Combiner会先预处理成如(the, 10000)
Input and Output Types
有预制的输入模式,用户也可以自定义reader接口
Skipping Bad Records
对于某些会导致MapReduce崩溃的坏记录,一个option是直接跳过
Local Execution
为了方便debug,MapReduce也可以在单个机器上运行
Status Information
主节点会运行一个内置HTTP服务器,展示MapReduce任务的一系列状态信息
Counters
如果用户想记录某些事件的出现次数,可以用Counter对象
顺便记忆
derived data 派生数据
inverted index 倒排索引
conspire to obscure A with B 图谋用B掩盖A
conduit 管道,渠道
resilient 有弹性的
straggler 掉队者
a whole host of 一大堆
idempotent 幂等的